// We need the network to satisfy this request. Possibly for validating a conditional GET. boolean doExtensiveHealthChecks = !request.method().equals("GET"); HttpCodec httpCodec = streamAllocation.newStream(client, chain, doExtensiveHealthChecks); RealConnection connection = streamAllocation.connection();
private RealConnection findConnection(int connectTimeout, int readTimeout, int writeTimeout, int pingIntervalMillis, boolean connectionRetryEnabled)throws IOException { boolean foundPooledConnection = false; RealConnection result = null; Route selectedRoute = null; Connection releasedConnection; Socket toClose; synchronized (connectionPool) { if (released) thrownew IllegalStateException("released"); if (codec != null) thrownew IllegalStateException("codec != null"); if (canceled) thrownew IOException("Canceled");
// 1、尝试使用已分配的连接 releasedConnection = this.connection; toClose = releaseIfNoNewStreams(); if (this.connection != null) { // 当前连接可用. result = this.connection; releasedConnection = null; } if (!reportedAcquired) { // If the connection was never reported acquired, don't report it as released! releasedConnection = null; }
// 2、尝试从连接池中获取一个连接 if (result == null) { // Attempt to get a connection from the pool. Internal.instance.acquire(connectionPool, address, this, null); if (connection != null) { foundPooledConnection = true; result = connection; } else { selectedRoute = route; } } } closeQuietly(toClose);
if (releasedConnection != null) { eventListener.connectionReleased(call, releasedConnection); } if (foundPooledConnection) { eventListener.connectionAcquired(call, result); } if (result != null) { // 如果从连接池中获取到了一个连接,就将其返回. return result; }
// If we need a route selection, make one. This is a blocking operation. boolean newRouteSelection = false; if (selectedRoute == null && (routeSelection == null || !routeSelection.hasNext())) { newRouteSelection = true; routeSelection = routeSelector.next(); }
synchronized (connectionPool) { if (canceled) thrownew IOException("Canceled");
if (newRouteSelection) { // Now that we have a set of IP addresses, make another attempt at getting a connection from // the pool. This could match due to connection coalescing. // 根据一系列的 IP地址从连接池中获取一个链接 List<Route> routes = routeSelection.getAll(); for (int i = 0, size = routes.size(); i < size; i++) { Route route = routes.get(i); // 从连接池中获取一个连接 Internal.instance.acquire(connectionPool, address, this, route); if (connection != null) { foundPooledConnection = true; result = connection; this.route = route; break; } } }
// 3、如果连接池中没有可用连接,则创建一个 if (!foundPooledConnection) { if (selectedRoute == null) { selectedRoute = routeSelection.next(); }
// Create a connection and assign it to this allocation immediately. This makes it possible // for an asynchronous cancel() to interrupt the handshake we're about to do. route = selectedRoute; refusedStreamCount = 0; result = new RealConnection(connectionPool, selectedRoute); acquire(result, false); } }
// If we found a pooled connection on the 2nd time around, we're done. if (foundPooledConnection) { eventListener.connectionAcquired(call, result); return result; }
// If another multiplexed connection to the same address was created concurrently, then // release this connection and acquire that one. if (result.isMultiplexed()) { socket = Internal.instance.deduplicate(connectionPool, address, this); result = connection; } } closeQuietly(socket);
longcleanup(long now){ int inUseConnectionCount = 0; int idleConnectionCount = 0; RealConnection longestIdleConnection = null; long longestIdleDurationNs = Long.MIN_VALUE;
// Find either a connection to evict, or the time that the next eviction is due. synchronized (this) { // 遍历所有的连接 for (Iterator<RealConnection> i = connections.iterator(); i.hasNext(); ) { RealConnection connection = i.next();
// If the connection is ready to be evicted, we're done. // 2、如果找到了一个可以被清理的连接,会尝试去寻找闲置时间最久的连接来释放 long idleDurationNs = now - connection.idleAtNanos; if (idleDurationNs > longestIdleDurationNs) { longestIdleDurationNs = idleDurationNs; longestIdleConnection = connection; } }
// maxIdleConnections 表示最大允许的闲置的连接的数量,keepAliveDurationNs表示连接允许存活的最长的时间。 // 默认空闲连接最大数目为5个,keepalive 时间最长为5分钟 // 3、如果空闲连接超过5个或者keepalive时间大于5分钟,则将该连接清理 if (longestIdleDurationNs >= this.keepAliveDurationNs || idleConnectionCount > this.maxIdleConnections) { connections.remove(longestIdleConnection); } elseif (idleConnectionCount > 0) { // 4、闲置的连接的数量大于0,停顿指定的时间(等会儿会将其清理掉,现在还不是时候) return keepAliveDurationNs - longestIdleDurationNs; } elseif (inUseConnectionCount > 0) { // All connections are in use. It'll be at least the keep alive duration 'til we run again. ///5、所有的连接都在使用中,5分钟后再清理 return keepAliveDurationNs; } else { // No connections, idle or in use. //6、没有连接 cleanupRunning = false; return -1; } }
privateintpruneAndGetAllocationCount(RealConnection connection, long now){ // 虚引用列表 List<Reference<StreamAllocation>> references = connection.allocations; // 遍历虚引用列表 for (int i = 0; i < references.size(); ) { Reference<StreamAllocation> reference = references.get(i); //如果虚引用StreamAllocation正在被使用,则跳过进行下一次循环 if (reference.get() != null) { i++; continue; }
// We've discovered a leaked allocation. This is an application bug. StreamAllocation.StreamAllocationReference streamAllocRef = (StreamAllocation.StreamAllocationReference) reference; String message = "A connection to " + connection.route().address().url() + " was leaked. Did you forget to close a response body?"; Platform.get().logCloseableLeak(message, streamAllocRef.callStackTrace);
// If this was the last allocation, the connection is eligible for immediate eviction. if (references.isEmpty()) { connection.idleAtNanos = now - keepAliveDurationNs; return0; } }
// Update the cache after combining headers but before stripping the // Content-Encoding header (as performed by initContentStream()). cache.trackConditionalCacheHit(); cache.update(cacheResponse, response); return response; } else { closeQuietly(cacheResponse.body()); } }
List<AsyncCall> executableCalls = new ArrayList<>(); boolean isRunning; synchronized (this) { for (Iterator<AsyncCall> i = readyAsyncCalls.iterator(); i.hasNext(); ) { AsyncCall asyncCall = i.next();
if (runningAsyncCalls.size() >= maxRequests) break; // Max capacity. if (runningCallsForHost(asyncCall) >= maxRequestsPerHost) continue; // Host max capacity.
E:\project\JavaExample\src\innerclassexample>javap -c Outer$Inner.class Compiled from "Outer.java" classinnerclassexample.Outer$Inner{ final innerclassexample.Outer this$0;
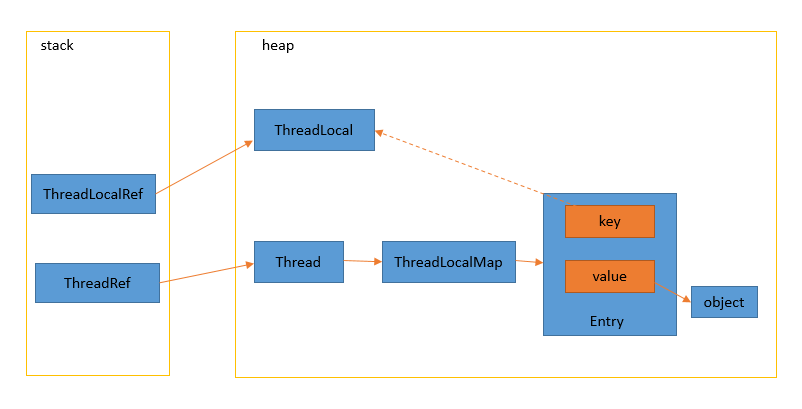
staticfinal ThreadLocal<Looper> sThreadLocal = new ThreadLocal<Looper>(); privatestaticvoidprepare(boolean quitAllowed){ if (sThreadLocal.get() != null) { thrownew RuntimeException("Only one Looper may be created per thread"); } sThreadLocal.set(new Looper(quitAllowed)); }
private Entry getEntry(ThreadLocal<?> key){ int i = key.threadLocalHashCode & (table.length - 1); Entry e = table[i]; if (e != null && e.get() == key) return e; else return getEntryAfterMiss(key, i, e); }
getEntryAfterMiss 方法:
整个过程中,如果遇到 key 为空的情况,会调用 expungeStaleEntry 方法进行擦除 Entry(Entry 中的 value 对象没有了强引用,自然会被回收)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e){ Entry[] tab = table; int len = tab.length;
while (e != null) { ThreadLocal<?> k = e.get(); if (k == key) return e; if (k == null) // 如果key值为null,则擦除该位置的Entry expungeStaleEntry(i); else i = nextIndex(i, len); e = tab[i]; } returnnull; }
privatevoidreplaceStaleEntry(ThreadLocal<?> key, Object value, int staleSlot){ Entry[] tab = table; int len = tab.length; Entry e;
int slotToExpunge = staleSlot; for (int i = prevIndex(staleSlot, len); (e = tab[i]) != null; i = prevIndex(i, len)) if (e.get() == null) slotToExpunge = i;
for (int i = nextIndex(staleSlot, len); (e = tab[i]) != null; i = nextIndex(i, len)) { ThreadLocal<?> k = e.get();