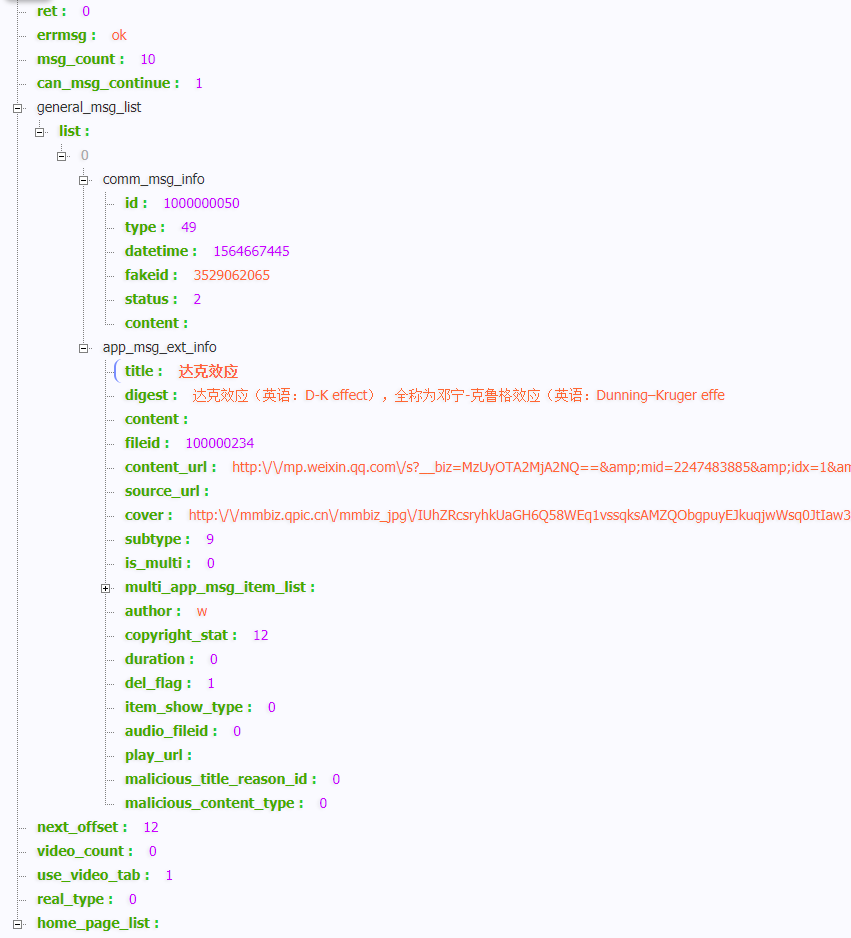
jaqen@jaqen-virtual-machine:~/Android/Projects/ijkplayer-android/android/contrib$ ./compile-openssl.sh all ==================== [*] check archs ==================== FF_ALL_ARCHS = armv5 armv7a arm64 x86 x86_64 FF_ACT_ARCHS = armv5 armv7a arm64 x86 x86_64
-------------------- [*] make NDK standalone toolchain -------------------- build on Linux x86_64 ANDROID_NDK=/home/jaqen/Android/Sdk/android-ndk-r14b IJK_NDK_REL=14.1.3816874 NDKr14.1.3816874 detected
-------------------- [*] make NDK standalone toolchain -------------------- build on Linux x86_64 ANDROID_NDK=/home/jaqen/Android/Sdk/android-ndk-r14b IJK_NDK_REL=14.1.3816874 NDKr14.1.3816874 detected HOST_OS=linux HOST_EXE= HOST_ARCH=x86_64 HOST_TAG=linux-x86_64 HOST_NUM_CPUS=4 BUILD_NUM_CPUS=8 Auto-config: --arch=arm ERROR: Failed to create toolchain.
解决办法是安装 python 后再执行编译。
1
sudo apt install python
编译 ffmpeg
1 2 3 4 5
# 清除 ffmpeg 的编译文件 ./compile-ffmpeg.sh clean
# 编译 ffmpeg ./compile-ffmpeg.sh all
执行 ./compile-ffmpeg.sh all 时出现编译错误:linux/perf_event.h: No such file or directory。
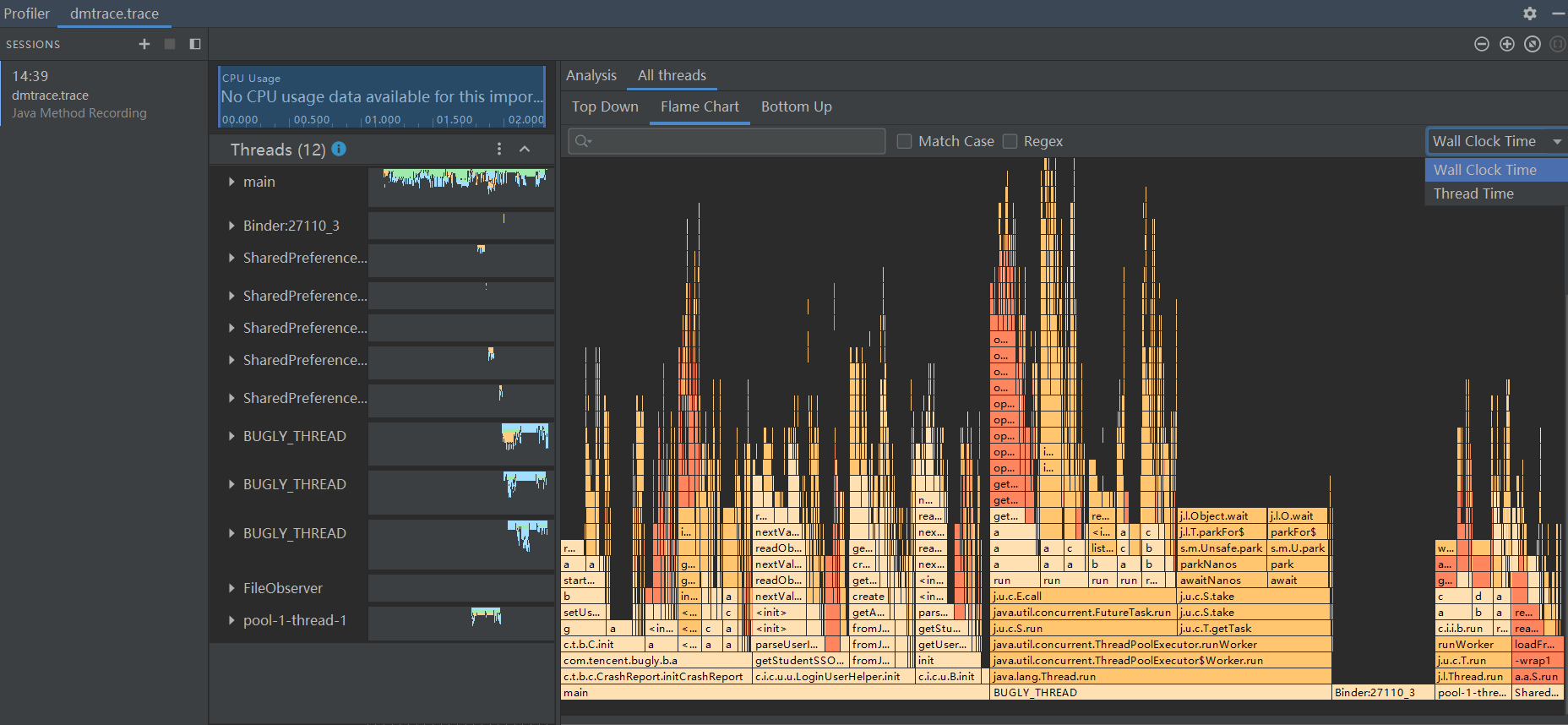
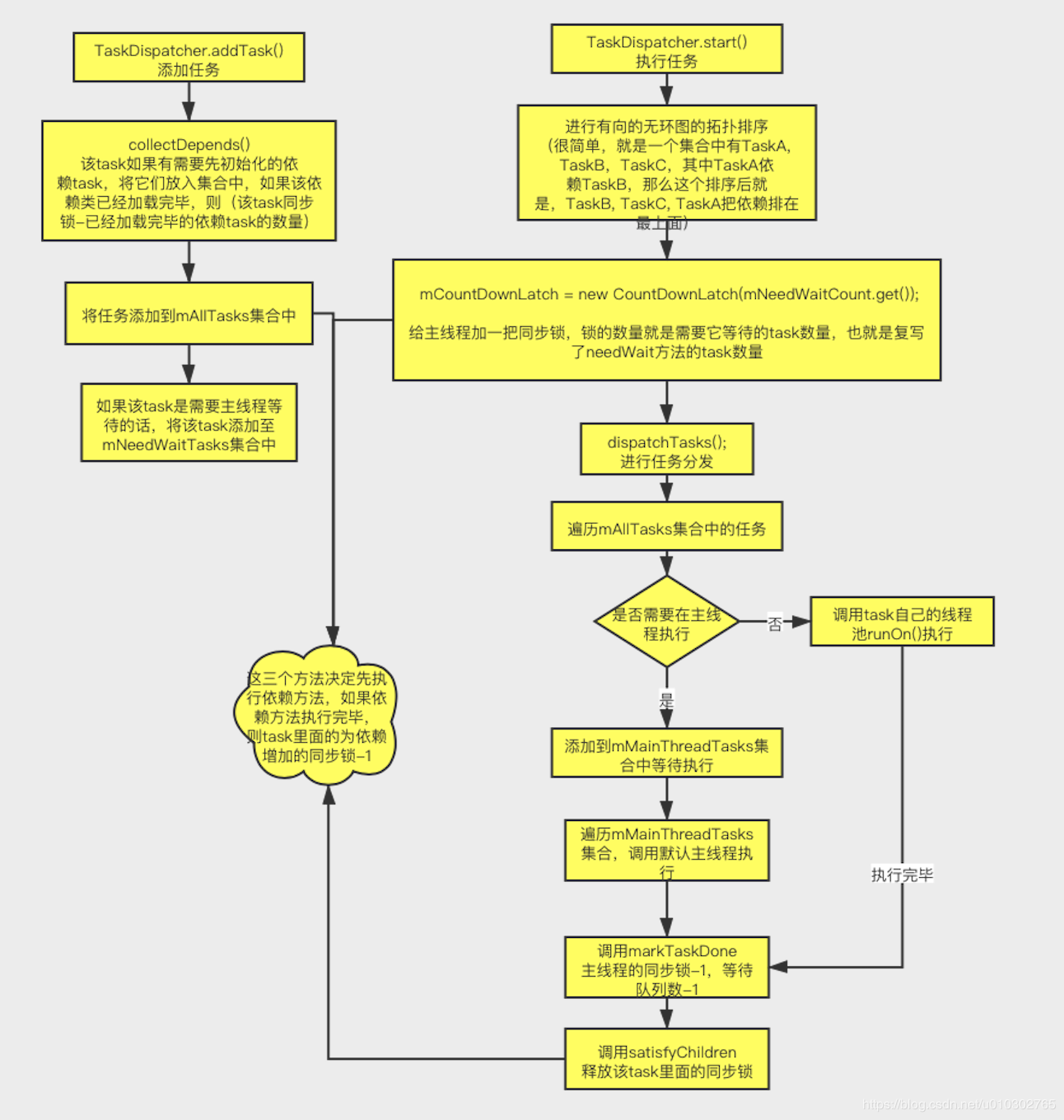
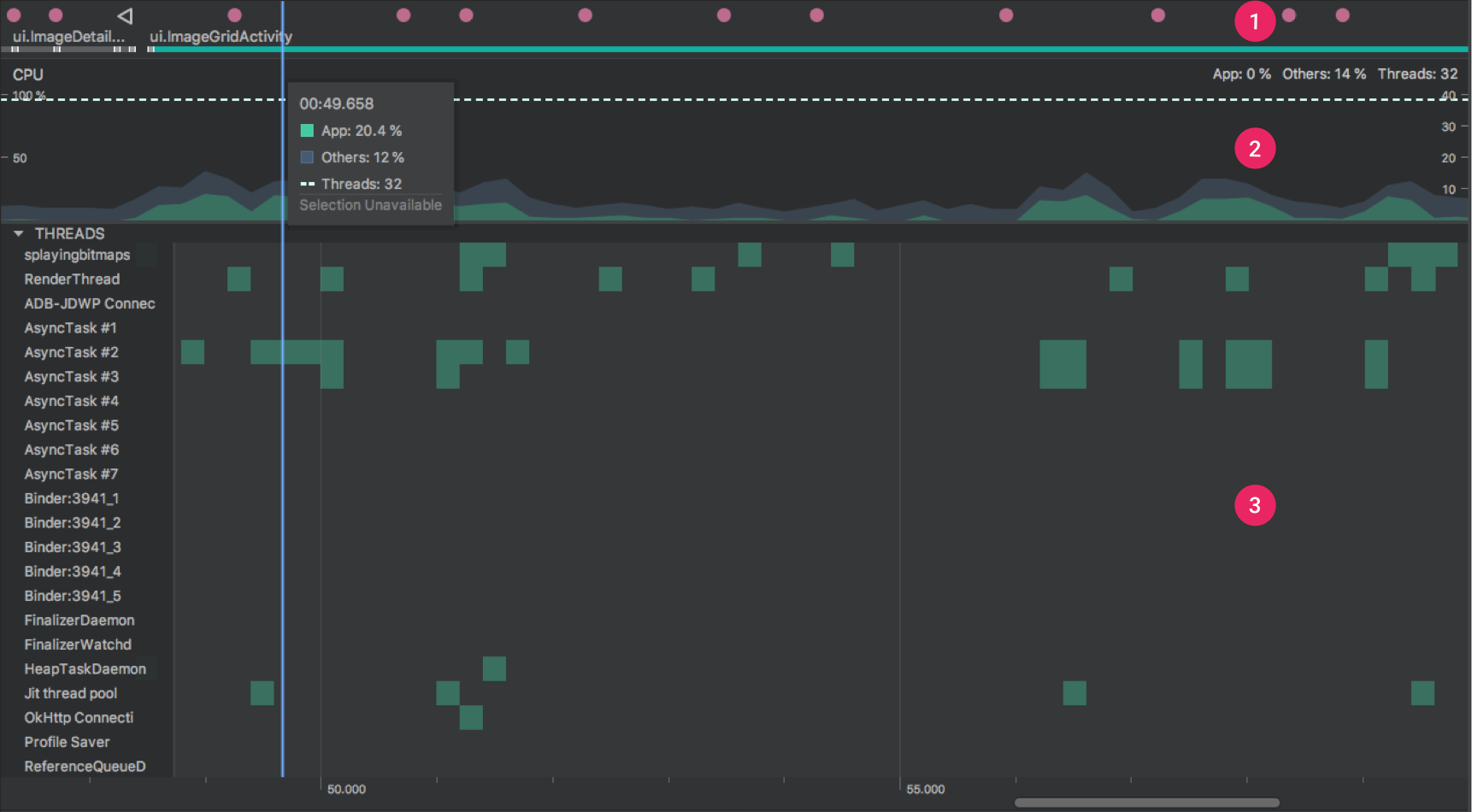
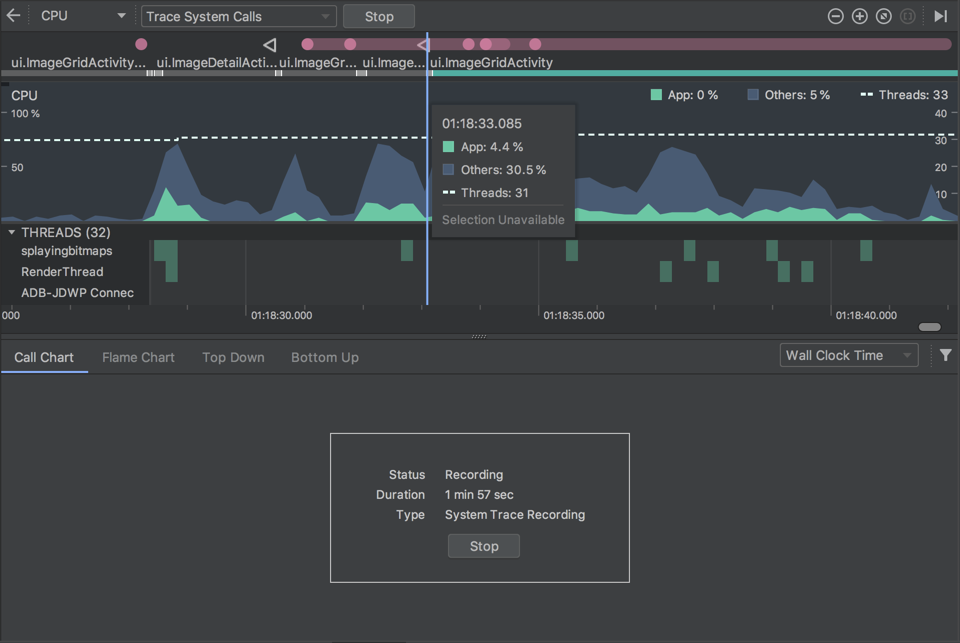
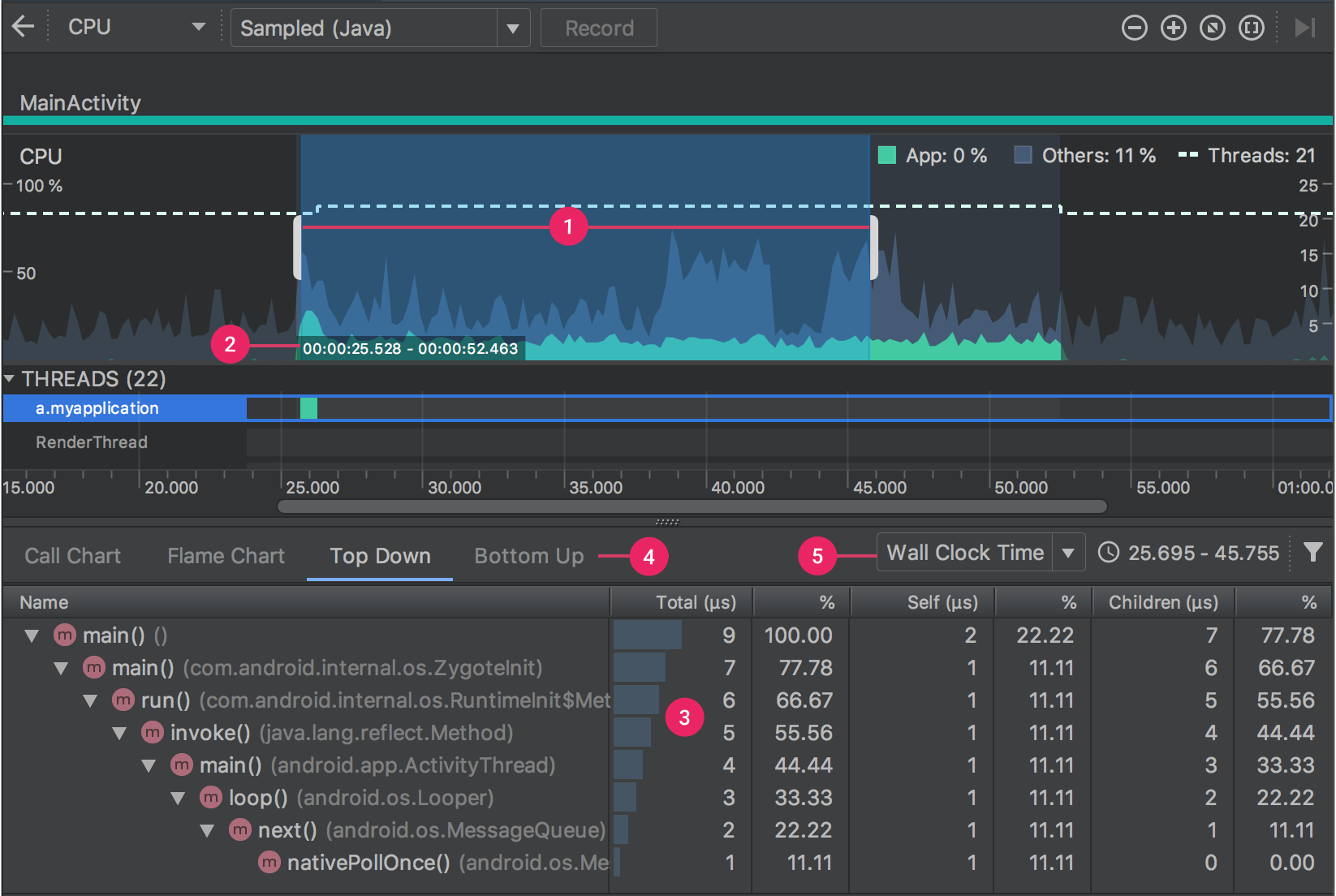
生成一个.trace后缀的文件,然后可以用 Android Studio 的 Profiler 添加打开它。
Wall Clock Time:表示实际经过的时间。包含线程在阻塞和等待的时间。
Thread Time:表示实际经过的时间减去线程没有占用 CPU 资源的那部分时间。
Flame Chart:火焰图。y 轴表示调用栈,每一层都是一个函数。调用栈越深,火焰就越高,顶部就是正在执行的函数,下方都是它的父函数。 x 轴表示抽样数,如果一个函数在 x 轴占据的宽度越宽,就表示它被抽到的次数多,即执行的时间长。注意,x 轴不代表时间,而是所有的调用栈合并后,按字母顺序排列的。
res = requests.get(url, headers=headers, proxies=proxies) with open('C:/Users/admin/Desktop/test/' + title + '.html', 'wb+') as f: f.write(res.content)
print(title + date + '成功')
except: print("不是图文消息")
if can_msg_continue == 1: returnTrue else: print('全部获取完毕') returnFalse
publicinteval(Expr expr){ if (expr instanceof Num) { return ((Num) expr).getValue(); } if (expr instanceof Sum) { Sum sum = (Sum) expr; return eval(sum.getLeft()) + eval(sum.getRight()); } thrownew IllegalArgumentException("Unknown expression"); }
kotlin 中使用when代替了switch,功能更强大。
在 when 中,我们使用 -> 表示执行某一分支后的操作,-> 之前是条件,可以是任何表达式。
1 2 3 4 5 6 7 8 9 10 11
when (x) { 0, 1 -> print("x == 0 or x == 1") else -> print("otherwise") }
when (x) { in1..10 -> print("x is in the range") in validNumbers -> print("x is valid") !in10..20 -> print("x is outside the range") else -> print("none of the above") }
回到任务本身。
1 2 3 4 5 6
funeval(e: Expr): Int = when (e) { is Num -> e.value is Sum -> eval(e.left) + eval(e.right) else -> throw IllegalArgumentException("Unknown expression") }
dataclassShop(val name: String, val customers: List<Customer>)
dataclassCustomer(val name: String, val city: City, val orders: List<Order>) { overridefuntoString() = "$name from ${city.name}" }
dataclassOrder(val products: List<Product>, val isDelivered: Boolean)
dataclassProduct(val name: String, val price: Double) { overridefuntoString() = "'$name' for $price" }
dataclassCity(val name: String) { overridefuntoString() = name }
Introduction
要求返回一个 Set,包含商店中所有的客户:
1 2 3 4 5
fun Shop.getSetOfCustomers(): Set<Customer> { // Return a set containing all the customers of this shop return customers.toSet() // return this.customers }
Filter Map
filter 方法返回一个包含所有满足指定条件元素的列表。
任务第一个要求返回指定城市所有客户的列表。
1 2 3 4
fun Shop.getCustomersFrom(city: City): List<Customer> { // Return a list of the customers who live in the given city return customers.filter { it.city == city } }
map 方法将指定的转换函数运用到原始集合的每一个元素,并返回一个转换后的集合。
任务第二个要求返回所有客户所在城市的 Set。
1 2 3 4
fun Shop.getCitiesCustomersAreFrom(): Set<City> { // Return the set of cities the customers are from return customers.map { it.city }.toSet() }
fun Customer.isFrom(city: City): Boolean { // Return true if the customer is from the given city returnthis.city == city }
fun Shop.checkAllCustomersAreFrom(city: City): Boolean { // Return true if all customers are from the given city return customers.all { it.isFrom(city) } }
fun Shop.hasCustomerFrom(city: City): Boolean { // Return true if there is at least one customer from the given city return customers.any { it.isFrom(city) } }
fun Shop.countCustomersFrom(city: City): Int { // Return the number of customers from the given city return customers.count { it.isFrom(city) } }
fun Shop.findFirstCustomerFrom(city: City): Customer? { // Return the first customer who lives in the given city, or null if there is none return customers.firstOrNull { it.isFrom(city) } }
FlatMap
flatmap:针对列表中的每一项根据指定的方法生成一个列表,最后将所有的列表拼接成一个列表返回。
1 2 3 4 5 6 7 8 9 10 11 12
// 返回一个客户所有已订购的产品 val Customer.orderedProducts: Set<Product> get() { // Return all products this customer has ordered return orders.flatMap { it.products }.toSet() } // 返回所有至少被一个客户订购过的商品集合 val Shop.allOrderedProducts: Set<Product> get() { // Return all products that were ordered by at least one customer return customers.flatMap { it.orderedProducts }.toSet() }
Max Min
max:返回集合中最大的元素。如果没有元素则返回 null。
maxby:使用函数参数计算的值作为比较对象。返回最大的元素中的值。
1 2 3 4 5 6 7 8 9 10 11
// 返回商店中订单数目最多的一个客户。 fun Shop.getCustomerWithMaximumNumberOfOrders(): Customer? { // Return a customer whose order count is the highest among all customers return customers.maxBy { it.orders.size } }
// 返回一个客户所订购商品中价格最高的一个商品 fun Customer.getMostExpensiveOrderedProduct(): Product? { // Return the most expensive product which has been ordered return orders.flatMap { it.products }.maxBy { it.price } }
Sort
kotlin 中可以通过 sortby指定排序的标准。
任务要求返回一个客户列表,客户的顺序是根据订单的数量由低到高。
1 2 3 4
fun Shop.getCustomersSortedByNumberOfOrders(): List<Customer> { // Return a list of customers, sorted by the ascending number of orders they made return customers.sortedBy { it.orders.size } }
Sum
sumby:将集合中所有元素按照指定的函数变换以后的结果累加。
任务要求计算一个客户所有已订购商品的价格总和。
1 2 3 4 5
fun Customer.getTotalOrderPrice(): Double { // Return the sum of prices of all products that a customer has ordered. // Note: a customer may order the same product several times. return orders.flatMap { it.products }.sumByDouble { it.price } }
GroupBy
groupBy方法返回一个根据指定条件分组好的 map。
任务要求返回来自每一个城市的客户的 map:
1 2 3 4
fun Shop.groupCustomersByCity(): Map<City, List<Customer>> { // Return a map of the customers living in each city return customers.groupBy { it.city } }
fun Shop.getCustomersWithMoreUndeliveredOrdersThanDelivered(): Set<Customer> { // Return customers who have more undelivered orders than delivered return customers.filter { val (delivered, undelivered) = it.orders.partition { it.isDelivered } delivered.size < undelivered.size }.toSet() }
Fold
fold:给定一个初始值,然后通过迭代对集合中的每一个元素执行指定的操作并将操作的结果累加。
任务要求返回所有客户都订购过的商品。
1 2 3 4 5
fun Shop.getSetOfProductsOrderedByEachCustomer(): Set<Product> { // Return the set of products that were ordered by each of the customers return customers.fold(allOrderedProducts, { orderedByAll, customer -> orderedByAll.intersect(customer.orderedProducts) })
fun Customer.hasOrderedProduct(product: Product) = orders.any { it.products.contains(product) }
// 所有购买了指定商品的客户列表 fun Shop.getCustomersWhoOrderedProduct(product: Product): Set<Customer> { // Return the set of customers who ordered the specified product return customers.filter { it.hasOrderedProduct(product) }.toSet() }
// 查找某个用户所有已发货的商品中最昂贵的商品 fun Customer.getMostExpensiveDeliveredProduct(): Product? { // Return the most expensive product among all delivered products // (use the Order.isDelivered flag) return orders.filter { it.isDelivered }.flatMap { it.products }.maxBy { it.price } }
// 查找指定商品被购买的次数 fun Shop.getNumberOfTimesProductWasOrdered(product: Product): Int { // Return the number of times the given product was ordered. // Note: a customer may order the same product for several times. return customers.flatMap { it.orders.flatMap { it.products } }.count { it == product } }
public Collection<String> doSomethingStrangeWithCollection(Collection<String> collection){ Map<Integer, List<String>> groupsByLength = Maps.newHashMap(); for (String s : collection) { List<String> strings = groupsByLength.get(s.length()); if (strings == null) { strings = Lists.newArrayList(); groupsByLength.put(s.length(), strings); } strings.add(s); }
int maximumSizeOfGroup = 0; for (List<String> group : groupsByLength.values()) { if (group.size() > maximumSizeOfGroup) { maximumSizeOfGroup = group.size(); } }
for (List<String> group : groupsByLength.values()) { if (group.size() == maximumSizeOfGroup) { return group; } } returnnull; }
方法的目的是:
将一个字符串集合按照长度分组,放入一个 map 中
求出 map 中所有元素 (String List) 的最大长度
根据步骤2的结果,返回 map 中字符串数目最多的那一组
1 2 3 4
fundoSomethingStrangeWithCollection(collection: Collection<String>): Collection<String>? { val groupsByLength = collection.groupBy { s -> s.length } return groupsByLength.values.maxBy { group -> group.size } }
dataclassMyDate(val year: Int, val month: Int, val dayOfMonth: Int)
funisLeapDay(date: MyDate): Boolean { val (year, month, dayOfMonth) = date
// 29 February of a leap year return isLeapYear(year) && month == 1 && dayOfMonth == 29 }
// Years which are multiples of four (with the exception of years divisible by 100 but not by 400) funisLeapYear(year: Int): Boolean = year % 4 == 0 && (year % 100 != 0 || year % 400 == 0)